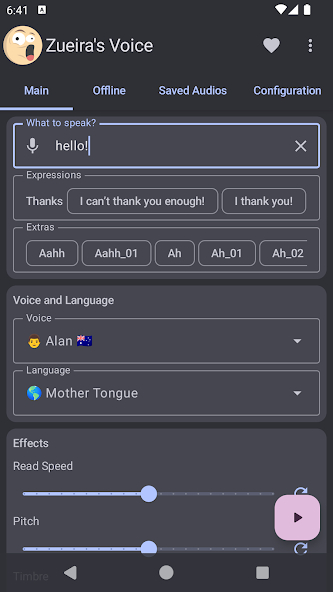
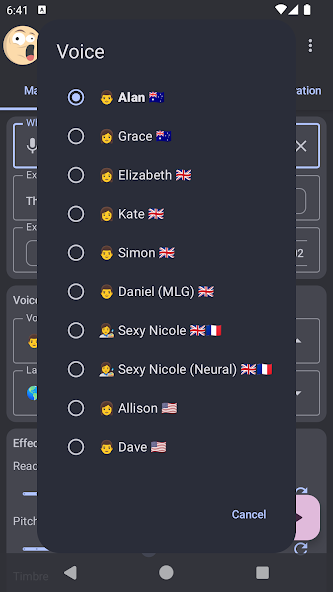
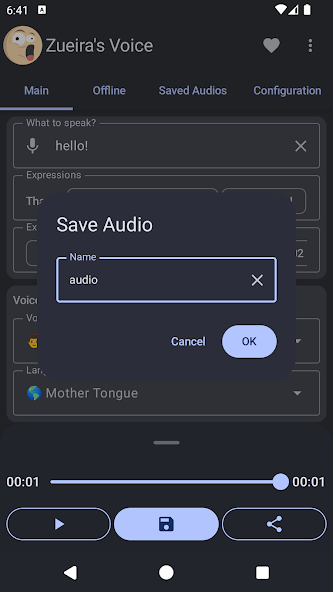
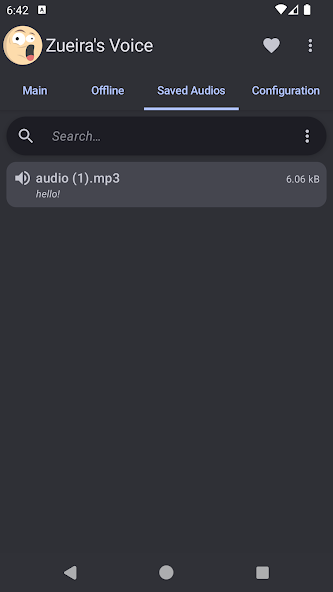
What is Zueira's Voice: Text to Speech Apps?
Zueira's Voice is a versatile text-to-speech toolkit designed to convert written content into natural, expressive audio suitable for a wide range of uses. The system combines advanced neural synthesis algorithms with customizable voice parameters to produce output that can be tuned for tone, rhythm, and emphasis. Users can adjust pitch, speaking rate, and prosody to match the desired persona, whether that is a calm narration, an energetic announcement, or a subtle background voice for ambient experiences. The engine supports multiple languages and accents, enabling content creators to reach diverse audiences without the need for native speakers. It also includes a library of preconfigured voice profiles that serve as starting points for creative modification. Integration options are flexible: the toolkit exposes programmable interfaces and batch conversion utilities that allow it to be incorporated into production pipelines, multimedia editors, and automated publishing workflows. Latency and throughput are optimized so that both on-demand playback and high-volume rendering are feasible. In addition, the architecture separates synthesis and audio post-processing, making it simple to chain effects like equalization, compression, and spatialization. For accessibility and utility, the product supports generating timed captions and phoneme-level markers to synchronize visuals and subtitles with speech output. Metadata embedding ensures rendered files carry contextual tags such as language, voice profile, and versioning information, which helps in content management systems. Security and privacy are handled with configurable settings that determine how input text is processed and stored—this allows deployments that prioritize ephemeral processing or long-term archives. Overall, Zueira's Voice aims to combine quality, control, and scalability so creators, enterprises, and developers can produce polished and intelligible synthesized speech that fits specific project requirements. Regular updates expand voice models, add domain-specific timbres for specialized narration, and broaden language coverage to accommodate emerging communication needs across industries worldwide with predictable licensing options available.
Under the hood, Zueira's Voice relies on a modular synthesis architecture that separates text analysis, linguistic processing, acoustic modeling, and waveform generation into discrete stages. The frontend performs tokenization, language detection, and prosody prediction, converting raw input into enriched phonetic sequences. These representations feed into neural acoustic models trained on diverse corpora to predict spectral envelopes, pitch contours, and timing information. A neural vocoder then transforms those acoustic parameters into high-fidelity waveforms with low artifacts and consistent intonation. Model ensembles and domain-adaptive fine-tuning are used to reduce voice drift when switching between content types, and multi-speaker training strategies allow the system to interpolate between timbres for richer, more natural results. The platform supports low-latency inference paths for interactive applications as well as higher-quality batched rendering for final production. Performance optimizations include quantized weights, optimized kernels for popular accelerators, and caching of repeated synthesis units to minimize computation for recurring phrases. Quality metrics combine objective measures such as spectral distortion and mel-cepstral error with subjective evaluations from listening tests to guide iteration. To facilitate synchronization with multimedia, Zueira's Voice outputs detailed timing markers, down to phoneme-level boundaries, and can generate alternative renditions with varied prosody for A/B testing. Audio outputs are produced in multiple formats and sample rates, and the post-processing chain supports customizable equalization, noise gating, and spatialization presets to match target playback environments. Logging captures anonymized synthesis traces to assist developers in diagnosing edge cases in prosody or pronunciation. Finally, the toolset is documented with example pipelines and code snippets illustrating integration into common content workflows, showing practical patterns for batching, error handling, and progressive refinement of voice profiles without exposing sensitive data. Developers can script adaptive behavior to switch voices by scene, implement conditional prosody rules, and export rendering reports for quality assurance and iteration on demand easily.
Zueira's Voice finds practical application across many industries where spoken audio enhances communication, comprehension, or user engagement. In e-learning and training, the tool can generate narrated lessons, multilingual explanations, and practice prompts that maintain consistent clarity across modules, helping learners absorb material at their own pace. In media and entertainment, producers use the system to prototype voiceovers, create character lines for early-stage demos, or produce localized versions of narration that preserve emotional intent. For accessibility services, it converts written interfaces and documentation into audible formats that improve inclusion for users who prefer or require audio. Customer-facing automation benefits from more natural-sounding prompts and confirmations in interactive voice response systems, where improved prosody reduces user frustration and speeds task completion. The platform also supports content creation workflows for podcasts, audiobook production, and game development by enabling batch rendering, voice blending, and scene-based voice assignment. In corporate communications, teams use synthesized briefings and announcements for consistent delivery across distributed offices, and compliance-heavy sectors can use neutral, machine-generated readings to minimize interpretive variance in official messaging. Marketing teams leverage dynamic audio personalization to tailor messages by demographic segments, campaign phases, or A/B variants without requiring fresh recording sessions for each iteration. Research and prototyping use cases include analyzing speech intelligibility across languages, stress-testing listening comprehension in noisy environments, and evaluating conversational agents with multiple synthetic personas. Because the system outputs time-aligned markers and variant renditions, creative teams can rapidly iterate on tone and timing to match visual content, making it a versatile component in post-production pipelines. The aggregate effect is to lower the marginal cost and time associated with producing high-quality spoken audio while expanding stylistic possibilities for projects of different scale and ambition. Small teams and solo creators benefit equally, accessing professional-grade vocal styles without long scheduling or bulky studio requirements today.
From a user experience standpoint, Zueira's Voice emphasizes intuitive controls and iterative refinement so creators can sculpt speech quickly without sacrificing depth. The interface exposes sliders and presets for delivery attributes such as warmth, clarity, assertiveness, and breathiness, while providing real-time auditioning so changes are immediately audible. For more granular control, advanced users can edit phonetic sequences, attach emphasis markers to words or syllables, and define pause durations between phrases. Templates and scene presets capture recurring voice setups so projects maintain consistency across episodes or content batches. Batch-processing tools let teams queue large script sets for overnight rendering, and revision history tracks changes to voice parameters to help revert or compare alternatives. Collaboration features include shared asset libraries, annotation tools for reviewers to comment on specific timestamps, and exportable renditions with embedded metadata for tracking versions. Developers and integrators receive SDKs and command-line utilities that let them orchestrate synthesis in build pipelines, trigger conditional rendering based on content attributes, and retrieve structured logs for auditing. The system supports tokenized inputs for dynamic content substitution, enabling personalized messages assembled at runtime. Quality control workflows are supported by automated checks that flag disallowed phoneme sequences or detect unnatural pacing, plus side-by-side comparison modes for AB listening tests. Accessibility considerations are baked into the UI with keyboard navigation, scalable text, and descriptive labels for screen reader compatibility. To speed onboarding, the product offers guided tours and a library of example projects demonstrating common patterns like multi-voice scenes, narration with sound beds, and multilingual publishing. The aggregate experience is designed to reduce friction while preserving the creative control professionals need to deliver polished, expressive audio. Users can export and archive voice presets, attach licensing metadata for reuse, and schedule recurring batch jobs that automatically apply chosen profiles to incoming scripts for continuous production flows.
Zueira's Voice is positioned as a flexible offering that supports a variety of commercial and operational arrangements tailored to organizational needs. Licensing is available in tiered packages that reflect usage volume, concurrent synthesis capacity, and access to premium voice profiles or specialized language packs. For production environments, enterprises can opt for deployment options that prioritize either on-premises processing or isolated cloud instances with predictable throughput SLAs, enabling cost modeling tied to rendering workloads. Pay-as-you-go arrangements suit sporadic creators and small teams, while volume commitments and annual packages deliver discounted rates for sustained high usage. The cost calculus typically considers rendered minutes, peak concurrency, and additional services such as batch acceleration or priority rendering queues. From a business perspective, adopting synthesized speech can reduce audio production timelines, cut studio and talent expenses, and accelerate localization, thereby lowering overall time-to-market for audio-rich deliverables. Teams often reallocate savings into higher quality scripting, sound design, or distribution, increasing the reach and polish of their content. Integration with analytics and reporting modules helps quantify return on investment by tracking rendered minutes, usage trends, and listener engagement when paired with playback metrics. Professional services are offered to assist with large-scale voice profile creation, domain-specific tuning, and migration of legacy audio assets into standardized synthesis workflows. Compliance and governance options let organizations define data retention windows, audit logs, and usage policies to align with internal practices and regulatory needs. For evaluation, sandboxed usage tiers provide realistic production-grade output so stakeholders can measure fit before scaling. Overall, Zueira's Voice aims to balance predictable cost structures with scalable performance, helping businesses convert text into high-quality speech while managing expenses and operational complexity. Teams benefit from predictable provisioning, flexible throughput expansion, and reporting dashboards that summarize per-project usage, costs, and quality assessments to guide future resource allocation and planning cycles.